Fairyland OCaml
Summary This Page
Preface Why Fairyland OCaml
Section: Library Gems
Good libraries deserve more explanaion.
Understanding Core.Command and Cmdliner
Section: Using Core
More comprehensive discussion after RWO.
What are [@@deriving compare, sexp_of, hash] for?
Section: OCaml Internals
🚧 Under Construction 🚧
Understanding Data Collections in Core

Preface
Fairyland OCaml 1 is a blog by Shiwei Weng to write my OCaml experience. I used to share OCaml snippets and understanding in our research group JHU PL Lab. I decided to port them here for a broader audience. The intuition often comes from my learning and research experience and the fantastic students from two functional programming courses at JHU.
The blog name is obviously from Real World OCaml.
Understanding Hashcons
Motivation
Aside. Data, value, object, component in this post means the same thing but from different perspectives.
Folklore. Hash-consing, as the name may suggest, is a hash value cons-ed (appended) after the immutable data (hash key). The immediate benefit is to reuse the hash value for the unchanged data. When used in recursive datatypes, the hash value of a data can be computed from the new payload part and the recursive part whose hash value is already cons-ed.
One-step further. It's obvious hash-consing is straightforward for immutable data. However, with immutable data, more aggresive designs can be made. Hash-consing libraries in real-world usually coincide with Flyweight pattern. They have the same targets:
- Encapsulate the object creation so that any distinct object is created just once.
- Generate and save a unique id to identify distinct objects.
- Save the hash value in the objects and choose a hash function that is aware of the saved hash values for its recursive components.
Some Concept (or Implementation) Details
Hash functions. With a unique id cons-ed, the datatype can provide a new equal function and a new hash function based on this id. In whole scenarios, three hash functions can be used.
- Global
hash. Language provide e.g.Hashtbl.hash. It's used internally for convenience. - Data's
hash. The hash function for your hash-consed data provided by users. - Hash-consing library
hash. The hash function for your hash-consed data provided by the library.
The existence and difference between 2 and 3 is not so clear depending on the library design. However, the ultimate target is to provide a better 2 with or without 3 than the old structural hash.
Weak references. Hash-consing library needs to provide an internal store to save the unique objects. This storage can be a weak array or a weak hash table. The internal storage should be weak because it should not prevent the garbage collection if any elements are not used outside.
Hash collision. Hash collision and hash resize is handled during the process to generate the unique id with the internal storage. The data's equal and data's hash function will be used. Data's hash collision outside of the internal storage is not concerned here.
Structural equality. A natural consequence of unique objects and ids is the structural equality check between two values can be replaced by physical equality. Refresh: structural equality checks whether two values per-component of their structures. Physical equality checks whether two values are at the same memory address. If all the objects is created inside the hash consing library, strutural equality can be replaced by phisical equality. = in OCaml approximates a structural equality check. == in OCaml is phisical equality check.
Reading library code
Now we are ready to look closely into two OCaml libraries backtracking/ocaml-hashcons (hashcons on opam) and fpottier/fix with Fix.HashCons (fix on opam).
backtracking/ocaml-hashcons
The repo is backtracking/ocaml-hashcons.
hashcons.mli defines the type:
type +'a hash_consed = private {
hkey: int;
tag : int;
node: 'a;
}
It's a bit subtle since hkey is computed value from the user-provided H.hash on the data before adding to the internal store. tag is the unique id which is either old from a previous object or new if added. node is the data before hash-consed.
The following code snippets are from test.ml :
open Hashcons
(* a quick demo of Hashcons using lambda-terms *)
type node =
| Var of string
| App of term * term
| Lam of string * term
and term = node hash_consed
(* the key here is to make a O(1) equal and hash functions, making use of the fact that sub-terms are already hash-consed and thus we can
1. use == on sub-terms to implement equal
2. use .tag from sub-terms to implement hash
*)
module X = struct
type t = node
let equal t1 t2 = match t1, t2 with
| Var s1, Var s2 -> s1 = s2
| App (t11, t12), App (t21, t22) -> t11 == t21 && t12 == t22
| Lam (s1, t1), Lam (s2, t2) -> s1 = s2 && t1 == t2
| _ -> false
let hash = function
| Var s -> Hashtbl.hash s
| App (t1, t2) -> t1.tag * 19 + t2.tag
| Lam (s, t) -> Hashtbl.hash s * 19 + t.tag
end
module H = Make(X)
let ht = H.create 17
let var s = H.hashcons ht (Var s)
let app t1 t2 = H.hashcons ht (App (t1,t2))
let lam s t = H.hashcons ht (Lam (s,t))
let x = var "x"
let delta = lam "x" (app x x)
let omega = app delta delta
let () = assert (var "x" == x)
let () = assert (app x x == app x x)
X.hash is the data's hash. Global hash is used both in X.hash inside of H.hashcons. X.equal uses physical equality for objects. X.hash also uses the unique ids for components. The last two asserts check the objects created at different application shares the same memory addresses.
Module Hashcons also provides Hset and Hmap. They're external containers which is aware of your hash-consed data. Don't confuse them with the internal storage, which is also a hash-based container.
fpottier/fix
The repo is fpottier/fix.
Fix.HashCons(ml,mli) looks very lightweighted because the internal storage is achieved by another module Fix.MEMOIZER.
type 'data cell =
{ id: int; data: 'data }
id is the unique id while data is your datatype to hash-cons. The another difference worth mentioning is with backtracking/ocaml-hashcons the user is in change of the objects pool getting from H.create while with Fix.HashCons the pool is shared. It's explained in HashCons.ml.
(* M : MEMOIZER *)
let make =
M.memoize (fun data -> { id = gensym(); data })
MEMOIZER is a module relying on the user-provide Map.S which contains find and add. No data's hash is required, but making MEMOIZER requires a HashedType. The result module of HashCons.Make provides a hash which relies on the unique id.
The demo code demos/hco
HashConsDemo.ml is challenging to read if one is not aware of these hash functions in use.
open Fix
module MySkeleton = struct
type 'a t =
| Leaf
| Node of int * 'a * 'a
let equal equal sk1 sk2 =
match sk1, sk2 with
| Leaf, Leaf ->
true
| Node (x1, l1, r1), Node (x2, l2, r2) ->
x1 = x2 && equal l1 l2 && equal r1 r2
| Node _, Leaf
| Leaf, Node _ ->
false
let hash hash sk =
match sk with
| Leaf ->
0
| Node (x, l, r) ->
x + hash l + hash r
end
type tree =
skeleton HashCons.cell
and skeleton =
S of tree MySkeleton.t [@@unboxed]
module M =
HashCons.ForHashedTypeWeak(struct
type t = skeleton
let equal (S sk1) (S sk2) =
MySkeleton.equal HashCons.equal sk1 sk2
let hash (S sk) =
MySkeleton.hash HashCons.hash sk
end)
let leaf () : tree =
M.make (S MySkeleton.Leaf)
let node x l r : tree =
M.make (S (MySkeleton.Node (x, l, r)))
let example() =
node 0
(leaf())
(leaf())
let () =
assert (example() == example());
Printf.printf "Size of example tree is %d.\n" (size (example()));
print_endline "Success."
MySkeleton provides equal and hash, which require another equal and hash as arguments respectively. The hash-consing aware equal and hash is provided in HashCons.ForHashedTypeWeak. The resulting code shares the same motivation as the previous demo.
Summary and Questions (To-do)
I am short on time to polish the post and complete all my to-do now. My motivation is the fixed point computation runs very slow on several test cases, and the profiling results show it's doing too much repeated structural hashing. The post mainly shares how to understand hash-consing libraries. If I may, I will rename both hash consing or flyweight to with_unique or with_uid.
Besides these two OCaml libraries, I also refer to wiki/Hashconing and papers
- Sylvain Conchon and Jean-Christophe Filliâtre. Type-Safe Modular Hash-Consing. In ACM SIGPLAN Workshop on ML, Portland, Oregon, September 2006.
- Implementing and reasoning about hash-consed data structures in Coq
How to bring hash-consing to Core is my immediate problem.
Furthermore, as string intern is widely used for many languages, why is hash-consing not the default implementation inside OCaml compilers?
The functions on the raw types need to be reimplemented with the hash cons-ed type with just tedious fmap. Is it another case for the Expression Problem or Open Recursion?
I am also interested in the implementation of camlp5/pa_ppx_hashcons and coq-core/Hashcons.
Understanding Core.Command and Cmdliner
Introduction
Command-line parse libraries e.g. Core.Command and Cmdliner are notoriously difficult to understand and use. The tension may come from people require a quick solution, while both these libraries target to be full-feathered tools with abstractions and concepts. This post aims to provide an understanding guide for them. Their official tutorials are at RWO/Command-Line Parsing and cmdliner/tutorial. I hope you can be much clear to jump back to them after reading this guide.
Four Concepts
Both libraires provide four levels of concepts:
| Concept | Stage | Composable | Core.Command | Cmdliner |
|---|---|---|---|---|
| Argument Parser | Step 4 | no | 'a Arg_type.t | 'a Arg.conv = 'a parser * 'a printer |
| Argument Handler | Step 3 | yes | 'a Param.t | 'a Term.t |
| Command Item | Step 2 | yes | unit Command.t | 'a Cmd.t |
| Driver | Step 1 | no | Command.run | Cmd.eval, Cmd.eval_value |
Argument Parser provides functions to parse a raw string to the expected type 'a. They both provide parsers inside Core/Command/Spec and Cmdliner/Predefined_converters for common types. Cmdliner.Arg.conv is a pair of a parser with a printer.
Argument Handler wraps a parser with extra properties to handle command-line argument e.g. whether it's required or optional, whether it's repeated, with a flag or not, the doc string for it. Argument Handler may not need Parsing in examples that a flag argument carries no values. The existence or not means a boolean parameter e.g. -v (rather than -log=WARNING).
In both libraries, Argument Handlers are not directed used by Drivers. Argument Handlers are packed into a Command Item, and then drivers take Command Item and perform the real parsing work. A Command Item for a whole sub-command e.g. push ... in git push .... You may have other sub-commands like git clone, git pull, and you need to group these Command Items into a compound Command Item.
In Table 1, The Column Stage lists the time order during a real command-line parsing.
- Step 1: Driver are usually the unique top function of your program. It takes the
Sys.argvand invodes your Command Item. - Step 2: Driver dispatches to the Command Item.
- Step 3: Argument Handler performs the parsing and handling, with the Argument Parser in it if having one.
Driver functions
Core.Command can only build up to a Command.t. It doesn't provide any driver functions. The driver function Core.Command.run is defined in another library core_unix.command_unix. It takes the Core.Command.t and start the work.
Cmdliner has a variant of driver functions e.g. Cmd.eval and Cmd.eval_value. Since it's supposed to be the unique top function, Cmd.eval returns a int (standard error code) that is used by exit.
It's a common myth that people seek to get the unboxed parsed result. Such a function is not even provided in Core.Command. It's do-able with Cmdliner.Cmd.eval_value : ... -> ?argv:string array -> 'a Cmd.t -> ('a Cmd.eval_ok, Cmd.eval_error) result. However, you need to tokenize to get argv yourself (Impatient readers can jump to Section Elimination).
Diagrams for Core.Command and Cmdliner
Both Core.Command and Cmdliner have two-layered compositional datatypes. An element in the inner layer is to parse one key-value pair (or key-only or value-only). For example, we're going to parse -v -a=1 -b=t 42.
The inner layer for Core.Command is a compositional Param.t. We will have four Param.t that are
bool Param.tfor-vint Param.tfor-a=1in which aint Arg_typeto parse1string Param.tfor-b=tin which astring Arg_typeto parsetint Param.tfor42in which aint Arg_typeto parse42
The inner layer for Cmdliner is a compositional Term.t. We will have four Term.t that are
bool Term.tfor-vint Term.tfor-a=1in which aint Arg.convto parse1string Term.tfor-b=tin which astring Arg.convto parsetint Term.tfor42in which aint Arg.convto parse42
The inner layer data are wrapped into outer layer data Core.Command.t or Cmdliner.Cmd.t via packing function Core.Command.basic or Cmdliner.Cmd.v. An outer layer data is usually used for argparsing one command-line case. It is also composable and is used to group sub-commands. Core.Command.group takes (string * Core.Command.t) list and returns a Core.Command.t. Cmdlinder.Cmd.group takes Cmdliner.Cmd.t list and returns a Cmdliner.Cmd.t.
Their diagrams are very alike in the respective of our four concepts. A rectangle corresponds to a type. An edge is a function that transforms datatype. A rounded rectangle is also a function but at an endpoint (It's rare. Only two driver functions and one Arg.flag). Four compositional datatypes Param.t Command.t Term.t Cmd.t should be in stacked rectangles (but here I just use a rectangle with double edges). I omit the doc-related components to make it clear.
---
title: Figure 1.1 - Diagram for Core.Command
---
graph LR
subgraph at [Argument Parser]
AT[Arg_type.t]
end
subgraph sp [Argument Handler]
subgraph fa [Flag & Anons]
CA1[Anons.t]
CF1[Flag.t]
CF2[no_arg : Flag.t]
end
AT --> |"Anons.(%:)"| CA1
AT --> |Param.required| CF1
P0[[Param.t]] --> |"Param.map"| P0
CA1--> |Param.anon| P0
CF1 --> |Param.flag| P0
CF2 --> |Param.flag| P0
end
subgraph sg [Command Item]
C0[[Command.t]] --> | Command.group | C0
end
P0 --> |Command.basic| C0
subgraph sd [Driver]
direction LR
Cr(Command.run)
C0 -.-> Cr
end
---
title: Figure 1.2 - Diagram for Cmdliner
---
graph LR
subgraph ap [Argument Parser]
AC[Arg.conv]
end
AC --> |Arg.pos| AT1
AC --> |Arg.opt| AT2
subgraph sa [Argument Handler]
subgraph at [Arg.t]
AT1[Arg.t]
AT2[Arg.t]
AT3(Arg.flag ~> Arg.t)
end
AT1 --> |Arg.value| P0
AT2 --> |Arg.value| P0
AT3 --> |Arg.value| P0
P0[[Term.t]] --> |"Term.($)"| P0
end
P0 --> |Cmd.v| C0
subgraph sg [Command Item]
direction LR
C0[[Cmd.v]] --> |Cmd.group| C0
end
subgraph sd [Driver]
direction LR
Cr(Cmd.eval)
Cv(Cmd.eval_value)
C0 .-> Cr
C0 .-> Cv
end
How Param.t and Term.t are made
A Core.Command.t consists of the flagged parameters and anonymous (flag-less) parameters. A Cmdlinder.t is consists of optional arguments and positional arguments. They are Argument Handlers. Note Argument Handlers use Argument Parsers.
In Core.Command, A primitive 'a Param.t can made up from ingredients
'a Arg_type.tparsesstringto'a'a Flag.tcan wrap'a Arg_type.tasrequired,optional, oroptional_with_default'bool Flag.trequires no'a Arg_type.t. Therefore its existence denotes atrueorfalse'a Anons.twhich wraps'a Arg_type.tParam.flagmakes'a Flag.ta'a Param.tParam.anonmakes'a Anons.ta'a Param.t
In Cmdlinder, the ingredients to make up a primitive 'a Term.t are:
'a Arg.convdefines both a parser and a printer for'aArg.optwraps'a Arg.convan optional flagged argument'a Arg.t.Arg.poswraps'a Arg.convand makes a positional argument at certain index'a Arg.tArg.flagmakes a pure flag optional argumentbool Arg.tArg.valuemakes'a Arg.ta'a Term.t
The listing and the diagram are not complete, but they are sufficient to illuminate.
Pack Argument Handler to Command Item
Driver functions takes a Command Item packed from a Argument Handler. Param.t and Term.t can compose just like parser combinator or prettyprinter. They should be Applicative (or also Contravariant ?)
Pack Command.Param.t to Command.t
The pack function for Command is Command.basic.
# #require "core";;
# open Core;;
# Command.Param.map;;
- : 'a Command.Spec.param -> f:('a -> 'b) -> 'b Command.Spec.param = <fun>
# #show Command.basic;;
val basic : unit Command.basic_command
# #show Command.basic_command;;
type nonrec 'result basic_command =
summary:string ->
?readme:(unit -> string) ->
(unit -> 'result) Command.Spec.param -> Command.t
Type Command.Spec.param is an alias for Command.Param.t. We can see the types for first argument and the return type of Command.Param.map, and the second-to-last argument of Command.basic_command, are all Command.Param.t. 'result is set to be unit in Command.basic.
The task left for users is to provide a function that maps parsed result 'a Param.t to (unit -> unit) Param.t.
The following two lines are equal. It's a partially applied Param.map from string Param.t to an unknown ~f : string -> '_weak:
# Command.Param.(%:);;
- : string -> 'a Command/2.Arg_type.t -> 'a Command.Spec.anons = <fun>
# Command.Param.string;;
- : string Command/2.Arg_type.t = <abstr>
# Command.Param.(map (anon ("filename" %: string)));;
- : f:(string -> '_weak1) -> '_weak1 Command.Spec.param = <fun>
# Command.(let s : string Param.Arg_type.t = Param.string in let a = Param.(%:) "filename" s in Param.map (Param.anon a));;
- : f:(string -> '_weak2) -> '_weak2 Command.Spec.param = <fun>
In the following example of Command.basic, our function (fun file () -> ignore file) satisfied the type requirement. The observation here is Command.basic requires an argument of type (unit -> unit) Command.Spec.param. The user comsume-all-parsed code is usually like Param.map a_b_c_param ~f:(fun a b c () -> ...; () ) : (unit -> unit) Command.Spec.param. The parsed result is passed before the last argument ().
# Command.basic ~summary:"fairy file" Command.Param.(map (anon ("filename" %: string)) ~f:(fun file () -> ignore file));;
- : Command.t = <abstr>
To make it familiar to RWO readers, we use let%map_open instead of Param.map. The code is equivalent to the above one:
# #require "ppx_jane";;
# let%map_open.Command file = (anon ("filename" %: string)) in file;;
- : string Command.Spec.param = <abstr>
# Command.basic ~summary:"fairy file" (let%map_open.Command file = (anon ("filename" %: string)) in fun () -> ignore file);;
- : Command.t = <abstr>
Pack Cmdliner.Term.t to Cmdliner.Cmd.t
Cmdliner uses pure (Term.const : 'a -> 'a t) and ap (Term.($) : ('a -> 'b) t -> 'a t -> 'b t) to compose Term.t. Unlike Command.basic, the user comsume-all-parsed code is usually like Term.(const (fun a b c -> ...; () )) $ a_param $ b_param $ c_param : unit Term.t. Term.v packs this value to get a Cmd.t, then this Cmd.t can be used in the driver function Cmd.eval.
# #require "cmdliner";;
# open Cmdliner;;
# Arg.(&);;
- : ('a -> 'b) -> 'a -> 'b = <fun>
# Arg.value;;
- : 'a Cmdliner.Arg.t -> 'a Term.t = <fun>
# Arg.string;;
- : string Arg.converter = (<fun>, <fun>)
# let file = Arg.(value & pos 0 string "default_name" (Arg.info []));;
val file : string Term.t = <abstr>
# Cmd.v (Cmd.info "fairy file") Term.((const (fun filename -> ignore filename)) $ file );;
- : unit Cmd.t = <abstr>
The difference between their approaches is Command puts the comsume-all-parsed function at last while Cmdliner puts it at first. They both use functional jargons e.g. let%map_open, Anon.(%:), Arg.(&) and Term.($). They help to compact the code, at the cost of confusing newcomers.
Syntax for Command-line Languages
It's not explicitly specified, but their design and APIs suggest (or check) possible syntax for the command-line languages. e.g. for the flag-less parts, Command treats them as anonymous arguments and allow the a sequence of them. The run-time validity of Param.t is less powerful than its static type. In this example, Anonymous int after a list of anonymous string causes an exception for its syntax.
# let my_param =
(let%map_open.Command str_lst = anon (sequence ("str" %: string))
and extra_int = anon ("int" %: int) in
fun () -> ());;
val my_param : (unit -> unit) Command.Spec.param = <abstr>
# Command.basic ~summary:"my_param" my_param ;;
Exception:
Failure
"the grammar [STR ...] INT for anonymous arguments is not supported because there is the possibility for arguments (INT) following a variable number of arguments ([STR ...]). Supporting such grammars would complicate the implementation significantly.".
Raised at Stdlib.failwith in file "stdlib.ml", line 29, characters 17-33
Called from Base__List0.fold in file "src/list0.ml", line 37, characters 27-37
Called from Command.Anons.Grammar.concat in file "command/src/command.ml", line 1000, characters 10-729
Called from Command.basic in file "command/src/command.ml", line 2373, characters 14-22
Called from Topeval.load_lambda in file "toplevel/byte/topeval.ml", line 89, characters 4-14
Cmdliner treats flag-less parts as positional arguments. The manual warns it's the user's duty to ensure the unique use of a position. Arg provides functions to either preciously points to one position index, or to range all, or to cover the left/right to a given position index. Duplication of position index will trigger run-time exception.
# let top_t =
let ai = Arg.info [] in
let str_lst : string list Term.t = Arg.(value & pos_all string [] ai) in
let extra_int : int Term.t = Arg.(value & pos 1 int 0 ai) in
let handle_all : (string list -> int -> unit) Term.t =
Term.const @@ fun _str_list _extra_int -> ()
in
Term.(handle_all $ str_lst $ extra_int);;
val top_t : unit Term.t = <abstr>
# let c =
let i = Cmd.info "" in
Cmd.v i top_t ;;
val c : unit Cmd.t = <abstr>
# Cmd.eval_value ~argv:[| "a"; "2" |] c;;
- : (unit Cmd.eval_ok, Cmd.eval_error) result = Stdlib.Ok (`Ok ())
# Cmd.eval_value ~argv:[| "a"; "b" |] c;;
: invalid value 'b', expected an integer
Usage: [OPTION]… [ARG]…
Try ' --help' for more information.
- : (unit Cmd.eval_ok, Cmd.eval_error) result = Stdlib.Error `Parse
Summary and Questions
To recap, after skipping documenting, escaping, error code, auto-completing, two of the most popular command-line libraries Core.Command and Cmdliner can be grasped via four concepts i.e. Argument Parser, Argument Handler, Command Item, and Driver. The diagram not only shows their internal relation, but also reveal the similarity between them. I don't have time to re-comment all their documents and tutorials from my viewpoint, but you're well equipped to go back for them ((for Command and for Cmdliner)) after this post.
Explicit syntax for for command-line languages and static safety typed parsing arise very interesting problems to me. I will delve into it in future posts.
Elimination
For command-line parsing, OCaml has build-in Sys.argv and standard library Arg module (tutorial).
⚠️ We can let Core.Command return the parsed result with a mutable reference, even its pack function and driver function requires a unit return value. When a functional program is not a functional program?
# let store = ref "" in
Command.basic ~summary:"fairy file" Command.Param.(map (anon ("filename" %: string)) ~f:(fun file () -> store := file; ()));;
- : Command.t = <abstr>
This post was improved thanks to feedback from @Khady.
Using Z3.Datatype
Introduction
This post is for explaining some concepts and show usage for library ocaml-z3 and my library fairy_z3. My long-time goal is to make Solve Anything easy in OCaml, and this is just a first step.
Roughly, z3 has coresponding data structures for expressions, primitive types and datatypes, as like these in OCaml. I will not discuss the details of logic or theory used in a SMT solver Z3. We can just treat it as versatile library.
To clarify,
- primitive types in OCaml, e.g.
int,boolean,float,string. - datatypes in OCaml, variants or records,
type t1 = Foo of int * string | Bar of int,type t2 = {a : int; b : float}.
In the current ocaml-z3 implementation, there is just one syntactic type Z3.Expr.expr for all z3 expressions and one syntactic type Z3.Sort.sort for the their types. To make this post more clear, we assume there is a better type definition that carries the correct sort of the expression. e.g. Z3Int 42 : Z3_int_exp. (It could be my second step for the long-time goal). Again,
- primitive types in z3, e.g.
Z3_int,Z3_boolean. - datatypes in Z3 e.g.
Z3_t1,Z3_t2.
Both OCaml and z3 provide the ways to construct and operate on primitive types. In OCaml, a datatype is easy to define. However, it takes some effect to construct a datatype with ocaml-z3 and use it. That's what this post and fairy_z3 targets.
Box, Unbox, Inject, Project
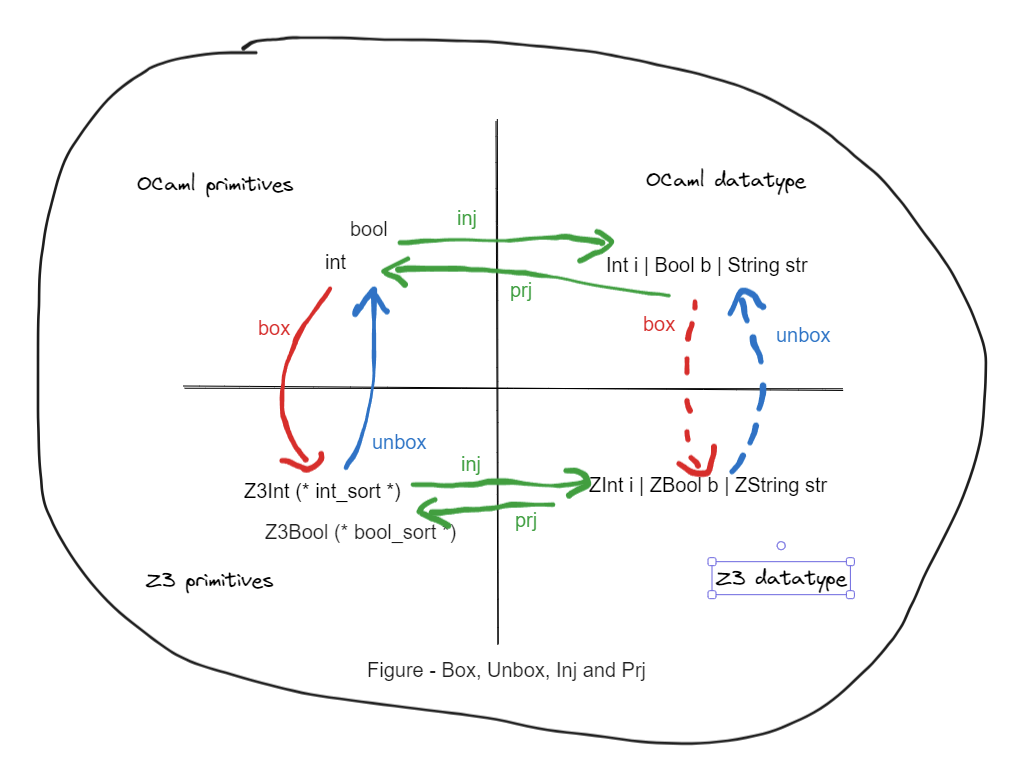
(Mermaid cannot handle nicely diagram in this isometric layout so I have to use excalidraw..)
We have four arrow groups:
-
(Solid green lines) In the OCaml land,
inj(inject) andprj(project) are supported by the language. Given the typet1above,injis to construct from primitive values to a value in typet1and theprjis to pattern match a value in typet1. -
(Solid red/blue lines) Between the primitive types of OCaml land and Z3 land. We choose the terms
boxandunboxto describe a value is to/from another representation in the perspective of OCaml. These functions are on-the-shelf.
let box_int : int -> Z3.Expr.expr =
fun i ->
Z3.Arithmetic.Integer.mk_numeral_i ctx i
let unbox_int : Z3.Expr.expr -> int =
fun e ->
e |> Z3.Arithmetic.Integer.get_big_int
|> Big_int_Z.int_of_big_int
Line 1, characters 22-34:
Error: Unbound module Z3
-
(Another solid green lines) In the Z3 land,
injandprjare achievable but tedious to write. We will demonstrate it in the later section and then advocate usingfairy_z3.ppxto derive them instead. -
(Dotten red/blue lines) Between the datatypes of OCaml land and Z3 land. The
boxandunboxfor datatypes are made of the above three groups.
Making Z3 Datatype by hand
Z3 has tutorial and api manual. Now I cannot remember how I figured out how to use it. Some z3 issues definitely helped.
If you have a glance of its api, you can find constructor, recognizer, accessor as well as sort and func_decl. Conceptually, func_decl are functions in Z3 land and sort are types in Z3 land. constructor, recognizer and accessor are certain functions and their functionalities are like the OCaml functions around OCaml datatypes but in Z3 land.
We first prepare the helper Z3 definitions in the group 2.
# #require "z3";;
# open Z3;;
# let ctx = mk_context [];;
val ctx : context = <abstr>
# let int_sort = Arithmetic.Integer.mk_sort ctx;;
val int_sort : Sort.sort = <abstr>
# let int_sort = Arithmetic.Integer.mk_sort ctx;;
val int_sort : Sort.sort = <abstr>
# let string_sort = Seq.mk_string_sort ctx;;
val string_sort : Sort.sort = <abstr>
# let box_int : int -> Z3.Expr.expr =
fun i ->
Z3.Arithmetic.Integer.mk_numeral_i ctx i
val box_int : int -> Expr.expr = <fun>
# let unbox_int : Z3.Expr.expr -> int =
fun e ->
e |> Z3.Arithmetic.Integer.get_big_int
|> Big_int_Z.int_of_big_int
val unbox_int : Expr.expr -> int = <fun>
# let box_string s = Seq.mk_string ctx s;;
val box_string : string -> Expr.expr = <fun>
# let unbox_string e = Seq.get_string ctx e;;
val unbox_string : Expr.expr -> string = <fun>
Then we define the example type t1. We also write a few functions ctor_*_ml(constructor), rzer_*_ml(recognizer), asor_*_ml(accessor) in OCaml land just for illustrating.
# type t1 = Foo of int * string | Bar of int;;
type t1 = Foo of int * string | Bar of int
# let ctor_foo_ml (i,s) = Foo (i,s);;
val ctor_foo_ml : int * string -> t1 = <fun>
# let rzer_foo_ml = function | Foo (_, _) -> true | _ -> false;;
val rzer_foo_ml : t1 -> bool = <fun>
# let asor_foo_0_ml = function | Foo (i, _) -> i | _ -> failwith "only foo";;
val asor_foo_0_ml : t1 -> int = <fun>
Now we are in Z3 land. We can make the constructors and the sort.
# Datatype.mk_constructor_s;;
- : context ->
string ->
Symbol.symbol ->
Symbol.symbol list ->
Sort.sort option list -> int list -> Datatype.Constructor.constructor
= <fun>
# let ctor_foo = Datatype.mk_constructor_s ctx "Foo"
(Symbol.mk_string ctx "is-Foo")
[ Symbol.mk_string ctx "Foo-0"; Symbol.mk_string ctx "Foo-1" ]
[ Some int_sort; Some string_sort ]
[ 1; 1 ];;
val ctor_foo : Datatype.Constructor.constructor = <abstr>
# let ctor_bar = Datatype.mk_constructor_s ctx "Bar"
(Symbol.mk_string ctx "is-Bar")
[ Symbol.mk_string ctx "Bar-0" ]
[ Some int_sort ] [ 1 ];;
val ctor_bar : Datatype.Constructor.constructor = <abstr>
# let t1_sort = Datatype.mk_sort_s ctx "t1_sort" [ ctor_foo; ctor_bar ];;
val t1_sort : Sort.sort = <abstr>
We make a constructor for each variant tag e.g. ctor_foo and in each tag we specify each payload type e.g. int (in `Foo of int * string) its name, sort, and whether it's recursive (non-zero means non-recursive).
A constructor is a variant tag description that used to make a sort. To apply a constructore, we need to first get the associated function a.k.a. func_decl in Z3 land. Then we apply this function in Z3 land via FuncDecl.apply.
# let ctor_f_foo = Datatype.Constructor.get_constructor_decl ctor_foo;;
val ctor_f_foo : FuncDecl.func_decl = <abstr>
# let ctor_f_bar = Datatype.Constructor.get_constructor_decl ctor_bar;;
val ctor_f_bar : FuncDecl.func_decl = <abstr>
# let e1_ = Foo (42, "camel");;
val e1_ : t1 = Foo (42, "camel")
# let e1 = ctor_foo_ml (42, "camel");;
val e1 : t1 = Foo (42, "camel")
# let e1_z3 = FuncDecl.apply ctor_f_foo [box_int 42; box_string "camel"];;
val e1_z3 : Expr.expr = <abstr>
# Expr.to_string e1_z3;;
- : string = "(Foo 42 \"camel\")"
Now we have already make a Z3 expression of t1_sort. We can also make constraint and solve on it. e.g. we can ask to solve (Foo x "camel") == (Foo 42 "camel") then x is 42.
# let solver = Solver.mk_solver ctx None;;
val solver : Solver.solver = <abstr>
# let e2_z3 = FuncDecl.apply ctor_f_foo [Arithmetic.Integer.mk_const_s ctx "x"; box_string "camel"];;
val e2_z3 : Expr.expr = <abstr>
# let solver_result = Solver.check solver [Boolean.mk_eq ctx e1_z3 e2_z3];;
val solver_result : Solver.status = Z3.Solver.SATISFIABLE
# match solver_result with Solver.SATISFIABLE ->
(match Solver.get_model solver with
| Some model -> Model.to_string model
| None -> "no model")
| _ -> "not sat";;
- : string = "(define-fun x () Int\n 42)"
Now we have all the ingredients to write inj functions in Z3 land and the box from OCaml to Z3.
# let inj_foo (ei,es) = FuncDecl.apply ctor_f_foo [ei; es];;
val inj_foo : Expr.expr * Expr.expr -> Expr.expr = <fun>
# let inj_bar ei = FuncDecl.apply ctor_f_bar [ei];;
val inj_bar : Expr.expr -> Expr.expr = <fun>
# let box_t1 = function
| Foo (i,s) -> inj_foo (box_int i, box_string s)
| Bar i -> inj_bar (box_int i);;
val box_t1 : t1 -> Expr.expr = <fun>
# box_t1 (Foo (101, "dog")) |> Expr.to_string;;
- : string = "(Foo 101 \"dog\")"
rzer_*(recognizer) and asor_*(accessor) are got from t1_sort.
# #show t1;;
type nonrec t1 = Foo of int * string | Bar of int
# let rzer_foo, rzer_bar =
match Datatype.get_recognizers t1_sort with
| [ rzer_foo; rzer_bar ] -> (rzer_foo, rzer_bar)
| _ -> failwith "recogniziers mismatch";;
val rzer_foo : FuncDecl.func_decl = <abstr>
val rzer_bar : FuncDecl.func_decl = <abstr>
# let (asor_foo_0, asor_foo_1), asor_bar_0 =
match Datatype.get_accessors t1_sort with
| [ [ asor_foo_0; asor_foo_1 ]; [ asor_bar_0 ] ] -> ((asor_foo_0, asor_foo_1), (asor_bar_0))
| _ -> failwith "accessors mismatch";;
val asor_foo_0 : FuncDecl.func_decl = <abstr>
val asor_foo_1 : FuncDecl.func_decl = <abstr>
val asor_bar_0 : FuncDecl.func_decl = <abstr>
Recognizers share the shape of variant cases. Accessors share the shape of variant cases and the inner payload types. It's also the same shape with the constructors.
# let ei = FuncDecl.apply rzer_foo [e1_z3];;
val ei : Expr.expr = <abstr>
# Expr.to_string ei;;
- : string = "((_ is Foo) (Foo 42 \"camel\"))"
Here comes the subtle question. FuncDecl.apply builds a function application in Z3 land, but it's just an unevaluated expression.
# let unbox_bool v = match Boolean.get_bool_value v with | L_TRUE -> true | L_FALSE -> false | _ -> failwith "L_UNDEF";;
val unbox_bool : Expr.expr -> bool = <fun>
# unbox_bool ei;;
Exception: Failure "L_UNDEF".
It's not a problem for the box direction because we can evaluate in OCaml land, box the result, and build the Z3 expression. To force the evaluation in Z3 land, we can use Expr.simplify ctx.
# let ei' = Expr.simplify ei None;;
val ei' : Expr.expr = <abstr>
# Expr.to_string ei';;
- : string = "true"
# unbox_bool ei';;
- : bool = true
Now we have all the ingredients to write prj functions in Z3 land and the unbox from Z3 to OCaml.
# let is_foo e = FuncDecl.apply rzer_foo [ e ];;
val is_foo : Expr.expr -> Expr.expr = <fun>
# let prj_foo_0 e = FuncDecl.apply asor_foo_0 [ e ];;
val prj_foo_0 : Expr.expr -> Expr.expr = <fun>
# let prj_foo_1 e = FuncDecl.apply asor_foo_1 [ e ];;
val prj_foo_1 : Expr.expr -> Expr.expr = <fun>
# let is_bar e = FuncDecl.apply rzer_bar [ e ];;
val is_bar : Expr.expr -> Expr.expr = <fun>
# let prj_bar_0 e = FuncDecl.apply asor_bar_0 [ e ];;
val prj_bar_0 : Expr.expr -> Expr.expr = <fun>
# let unbox_t1 e =
match e with
| _ when Expr.simplify (is_foo e) None |> unbox_bool ->
Foo
( Expr.simplify (prj_foo_0 e) None |> unbox_int,
Expr.simplify (prj_foo_1 e) None |> unbox_string )
| _ when Expr.simplify (is_bar e) None |> unbox_bool ->
Bar
( Expr.simplify (prj_bar_0 e) None |> unbox_int )
| _ -> failwith "not here";;
val unbox_t1 : Expr.expr -> t1 = <fun>
# unbox_t1 e1_z3;;
- : t1 = Foo (42, "camel")
All set for our expected functions!
Making Z3 Datatype by fairy magic
If you don't want to write the above functions, just use fairy_z3.ppx. To check the generated function, change [@@deriving ..] to [@@deriving_inline ..] [@@@end].
type t1 = Foo of int * string | Bar of int
[@@deriving z3 ~flag ~bv_width:52]
Summary and To-do
- Read (ocaml-)z3 source code to understand its datatype API better.
- Support more type constructors in OCaml.
- Allow more customizing for primitives box and unbox function.
- Make it more easier to use.
- Add more testing.
(Extra) Reconciling datatypes
There is tiny mismatch between the an OCaml type and a z3 datatype. OCaml's primitive types e.g. int lives outside of t1 while in (current) Z3 all expressions are Z3.Expr.expr. To reconcile this, we can also rewrite t1 to t2 to make t2 aligns with Z3.Expr.expr. Then we can define just one box function better_box to cover all cases.
# #show_type t1;;
type nonrec t1 = Foo of int * string | Bar of int
# type _ t2 =
| Int : int -> int t2
| String : string -> string t2
| Foo : int t2 * string t2 -> _ t2
| Bar : int t2 -> _ t2;;
type _ t2 =
Int : int -> int t2
| String : string -> string t2
| Foo : int t2 * string t2 -> 'a t2
| Bar : int t2 -> 'b t2
# Foo (Int 42, String "ml");;
- : 'a t2 = Foo (Int 42, String "ml")
# let better_box (e_ml : _ t2) : Z3.Expr.expr = failwith "not implemented";;
val better_box : 'a t2 -> Expr.expr = <fun>
What are [@@deriving compare, sexp_of, hash] for?
Real World OCaml has a dedicated chapter Maps and Hash Tables. It's an excellent tutorial to start with data containers in Jane Street's core (or Base), an alternative to the OCaml standard library stdlib. For both core and stdlib, elements need to provide required functions to be put into containers. The tutorial gives examples of elements with hand-written functions and derived functions.
open Core
module Book = struct
module T = struct
type t = { title : string; isbn : string }
let compare t1 t2 =
let cmp_title = String.compare t1.title t2.title in
if cmp_title <> 0 then cmp_title else String.compare t1.isbn t2.isbn
let sexp_of_t t : Sexp.t = List [ Atom t.title; Atom t.isbn ]
end
include T
include Comparator.Make (T)
end
open Core
module Book = struct
module T = struct
type t = { title : string; isbn : string } [@@deriving compare, sexp_of]
end
include T
include Comparator.Make (T)
end
Let's focus in what's inside of T. In this post, we will figure out one question:
What are [@@deriving compare, sexp_of, hash] for, as the post title askes?
We will answer this question from the user-code side, and left the explanation from the library-code side for the future.
Deriving Functions
These ppx deriver are janestreet/ppx_compare for equal and compare, janestreet/ppx_sexp_conv for sexp_of and of_sexp, and janestreet/ppx_hash for hash and hash_fold.
A quick way to inspect the deriving result is to change [@@deriving <ppx>] to [@@deriving_inline <ppx>] [@@@end] so there we can read the generated code between tags.
The idea of all these function deriver are type-based structural traversal. Don't be disturbed by the variable names in the generated code.
type foo1 = P1 of int * string [@@deriving_inline equal]
let _ = fun (_ : foo1) -> ()
let equal_foo1 =
(fun a__008_ b__009_ ->
if Stdlib.( == ) a__008_ b__009_ then true
else
match (a__008_, b__009_) with
| P1 (_a__010_, _a__012_), P1 (_b__011_, _b__013_) ->
Stdlib.( && )
(equal_int _a__010_ _b__011_)
(equal_string _a__012_ _b__013_)
: foo1 -> foo1 -> bool)
let _ = equal_foo1
[@@@end]
equal is straightforward. Two values are equal if they are physically equal i.e. at the same memory address. Otherwises, they need to be equal piecewise-ly. Core doesn't shadow OCaml vanilla standard library Stdlib.
type foo2 = P2 of int * string [@@deriving_inline compare]
let _ = fun (_ : foo2) -> ()
let compare_foo2 =
(fun a__014_ b__015_ ->
if Stdlib.( == ) a__014_ b__015_ then 0
else
match (a__014_, b__015_) with
| P2 (_a__016_, _a__018_), P2 (_b__017_, _b__019_) -> (
match compare_int _a__016_ _b__017_ with
| 0 -> compare_string _a__018_ _b__019_
| n -> n)
: foo2 -> foo2 -> int)
let _ = compare_foo2
[@@@end]
compare is similar to equal. Stdlib.compare : 'a -> 'a -> int the polymorphic compare is not used in Core, however, the convertion should be observed: compare x y returns 0 if x is equal to y, a negative integer if x is less than y, and a positive integer if x is greater than y.
type foo3 = P3 of int * string [@@deriving_inline sexp]
let _ = fun (_ : foo3) -> ()
let foo3_of_sexp =
(let error_source__022_ = "src-ocaml/elements.ml.foo3" in
function
| Sexplib0.Sexp.List
(Sexplib0.Sexp.Atom (("p3" | "P3") as _tag__025_) :: sexp_args__026_) as
_sexp__024_ -> (
match sexp_args__026_ with
| [ arg0__027_; arg1__028_ ] ->
let res0__029_ = int_of_sexp arg0__027_
and res1__030_ = string_of_sexp arg1__028_ in
P3 (res0__029_, res1__030_)
| _ ->
Sexplib0.Sexp_conv_error.stag_incorrect_n_args error_source__022_
_tag__025_ _sexp__024_)
| Sexplib0.Sexp.Atom ("p3" | "P3") as sexp__023_ ->
Sexplib0.Sexp_conv_error.stag_takes_args error_source__022_ sexp__023_
| Sexplib0.Sexp.List (Sexplib0.Sexp.List _ :: _) as sexp__021_ ->
Sexplib0.Sexp_conv_error.nested_list_invalid_sum error_source__022_
sexp__021_
| Sexplib0.Sexp.List [] as sexp__021_ ->
Sexplib0.Sexp_conv_error.empty_list_invalid_sum error_source__022_
sexp__021_
| sexp__021_ ->
Sexplib0.Sexp_conv_error.unexpected_stag error_source__022_ sexp__021_
: Sexplib0.Sexp.t -> foo3)
let _ = foo3_of_sexp
let sexp_of_foo3 =
(fun (P3 (arg0__031_, arg1__032_)) ->
let res0__033_ = sexp_of_int arg0__031_
and res1__034_ = sexp_of_string arg1__032_ in
Sexplib0.Sexp.List [ Sexplib0.Sexp.Atom "P3"; res0__033_; res1__034_ ]
: foo3 -> Sexplib0.Sexp.t)
let _ = sexp_of_foo3
[@@@end]
sexp_of and of_sexp are for serialization and deserialization. More details are at RWO Chapter Data Serialization with S-Expressions.
type foo4 = P4 of int * string [@@deriving_inline hash]
let _ = fun (_ : foo4) -> ()
let (hash_fold_foo4 :
Ppx_hash_lib.Std.Hash.state -> foo4 -> Ppx_hash_lib.Std.Hash.state) =
(fun hsv arg ->
match arg with
| P4 (_a0, _a1) ->
let hsv = hsv in
let hsv =
let hsv = hsv in
hash_fold_int hsv _a0
in
hash_fold_string hsv _a1
: Ppx_hash_lib.Std.Hash.state -> foo4 -> Ppx_hash_lib.Std.Hash.state)
let _ = hash_fold_foo4
let (hash_foo4 : foo4 -> Ppx_hash_lib.Std.Hash.hash_value) =
let func arg =
Ppx_hash_lib.Std.Hash.get_hash_value
(let hsv = Ppx_hash_lib.Std.Hash.create () in
hash_fold_foo4 hsv arg)
in
fun x -> func x
let _ = hash_foo4
[@@@end]
Here are the most complex functions. hash_fold is a state-passing function to perform the hashing payload. hash wraps hash_fold by providing an initial hash state via Hash.create () and converting the hash result to int via Hash.get_hash_value.
It implies if we need a cutsom hash function, implementing hash_fold to perform hashing and providing the same wrapping hash here.
Further explanation can be found at doc for Base.Hasher.S and the ppx_hash/design_doc. In short, hash_fold should take care of not only the values in the structure not also the structure itself, to avoid easily hash collision.
It becomes tricky when a Core-container is used as an element and this element is intended to be used in a container requiring hash, e.g. putting this Int_set_as_element in a Hash_set.
module Int_set_as_element = struct
module T = struct
type t = Set.M(Int).t [@@deriving_inline compare, sexp_of, hash]
let _ = fun (_ : t) -> ()
let compare =
(fun a__035_ b__036_ -> Set.compare_m__t (module Int) a__035_ b__036_
: t -> t -> int)
let _ = compare
let sexp_of_t =
(fun x__037_ -> Set.sexp_of_m__t (module Int) x__037_
: t -> Sexplib0.Sexp.t)
let _ = sexp_of_t
let (hash_fold_t :
Ppx_hash_lib.Std.Hash.state -> t -> Ppx_hash_lib.Std.Hash.state) =
fun hsv arg -> Set.hash_fold_m__t (module Int) hsv arg
and (hash : t -> Ppx_hash_lib.Std.Hash.hash_value) =
let func = Set.hash_m__t (module Int) in
fun x -> func x
let _ = hash_fold_t
and _ = hash
[@@@end]
end
include T
include Comparator.Make (T)
end
let _ = Set.empty (module Int_set_as_element)
let _ = Hash_set.create (module Int_set_as_element)
Both Set.hash_m__t and Set.hash_fold_m__t requires a first-class module implementing Hasher.S (which requires hash_fold_t). In this example, the module is Int. Int is a build-in module containing hash and hash_fold. If this is Your_data rather than Int, the generated code above for Set.M(Your_data).t will have Set.hash_m__t (module Your_data) and Set.hash_fold_m__t (module Your_data). Therefore, Your_data have to provide hash and hash_fold functions.
This can explain why Base.Hash_set.Key contains hash and no hash_fold, but ppx_hash still derives both hash and hash_fold.
p.s. I don't claim this design is good.
What is polymorphic compare?
The compare function
OCaml's polymorphic compare (or Stdlib.compare) is tempting to use but hard to reason.
Polymorphic compare in the manual says:
val (=) : 'a -> 'a -> bool
e1 = e2tests for structural equality ofe1ande2. Mutable structures (e.g. references and arrays) are equal if and only if their current contents are structurally equal, even if the two mutable objects are not the same physical object. Equality between functional values raisesInvalid_argument. Equality between cyclic data structures may not terminate.
Intuitionally, it compares two values structurally for their representations in memory.
This function is error-prone. A quick example to show here is to compare two values of IntSet. They are equal respecting their elements but unequal respecting their memory objects. Objdump is from favonia/ocaml-objdump. Stdlib.Set uses a balance-tree in the implementation. A tree containing two elements has multiple morphs to be balanced.
# module IntSet = Set.Make(Int);;
# let a = IntSet.(add 1 (singleton 0));;
val a : IntSet.t = <abstr>
# let b = IntSet.(add 0 (singleton 1));;
val b : IntSet.t = <abstr>
# a = b;;
- : bool = false
# IntSet.equal a b;;
- : bool = true
# #require "objdump";;
# Format.printf "@[%a@]@." Objdump.pp a;;
variant0(int(0),int(0),variant0(int(0),int(1),int(0),int(1)),int(2))
- : unit = ()
# Format.printf "@[%a@]@." Objdump.pp b;;
variant0(variant0(int(0),int(0),int(0),int(1)),int(1),int(0),int(2))
- : unit = ()

compare in the source
In the source, Stdlib.compare is provided as an FFI, and the actual implementation is in the C code of the runtime:
(* https://github.com/ocaml/ocaml/blob/trunk/stdlib/stdlib.ml#L72 *)
external compare : 'a -> 'a -> int = "%compare"
(* https://github.com/ocaml/ocaml/blob/trunk/runtime/compare.c#L339 *)
CAMLprim value caml_compare(value v1, value v2)
{
intnat res = compare_val(v1, v2, 1);
if (res < 0)
return Val_int(LESS);
else if (res > 0)
return Val_int(GREATER);
else
return Val_int(EQUAL);
}
The other sibing functions are also wrapping compare_val e.g. <>(notequal), <(lessthan), <=(lessequal) and the implementation is easy to infer. The third argument total is only set to 1 for caml_compare (a.k.a Stdlib.compare) and 0 otherwise.
// https://github.com/ocaml/ocaml/blob/trunk/runtime/compare.c#L88C42-L88C42
static intnat compare_val(value v1, value v2, int total)
{
struct compare_stack stk;
intnat res;
stk.stack = stk.init_stack;
stk.limit = stk.stack + COMPARE_STACK_INIT_SIZE;
res = do_compare_val(&stk, v1, v2, total);
compare_free_stack(&stk);
return res;
}
campare_val prepares a stack and invokes a worker function do_compare_val to perform the comparison. do_compare_val performs the structural comparison on the low-level representations. By keeping only the tag cases, a simplified do_compare_val is:
static intnat do_compare_val(struct compare_stack* stk,
value v1, value v2, int total)
{
struct compare_item * sp;
tag_t t1, t2;
sp = stk->stack;
while (...) {
while (...) {
if (v1 == v2 && total) goto next_item;
if (Is_long(v1)) {
if (v1 == v2) goto next_item;
if (Is_long(v2))
return Long_val(v1) - Long_val(v2);
switch (Tag_val(v2)) {
case Forward_tag:
v2 = Forward_val(v2);
continue;
case Custom_tag: {
int res = compare(v1, v2);
if (Caml_state->compare_unordered && !total) return UNORDERED;
if (res != 0) return res;
goto next_item;
}
default: /*fallthrough*/;
}
return LESS; /* v1 long < v2 block */
}
if (Is_long(v2)) {
// ... symmetry of the above code
}
return GREATER; /* v1 block > v2 long */
}
t1 = Tag_val(v1);
t2 = Tag_val(v2);
if (t1 != t2) {
if (t1 == Forward_tag) { v1 = Forward_val (v1); continue; }
if (t2 == Forward_tag) { v2 = Forward_val (v2); continue; }
if (t1 == Infix_tag) t1 = Closure_tag;
if (t2 == Infix_tag) t2 = Closure_tag;
if (t1 != t2)
return (intnat)t1 - (intnat)t2;
}
switch(t1) {
case Forward_tag: {
v1 = Forward_val (v1);
v2 = Forward_val (v2);
continue;
}
case String_tag: // ... string case
case Double_tag: // ... double case
case Double_array_tag: // ... double array case
case Abstract_tag:
case Closure_tag:
case Infix_tag:
case Cont_tag: // ... invalid cases
case Object_tag: {
intnat oid1 = Oid_val(v1);
intnat oid2 = Oid_val(v2);
if (oid1 != oid2) return oid1 - oid2;
break;
}
case Custom_tag: {
int res;
int (*compare)(value v1, value v2) = Custom_ops_val(v1)->compare;
/* Hardening against comparisons between different types */
if (compare != Custom_ops_val(v2)->compare) {
return strcmp(Custom_ops_val(v1)->identifier,
Custom_ops_val(v2)->identifier) < 0
? LESS : GREATER;
}
if (compare == NULL) {
compare_free_stack(stk);
caml_invalid_argument("compare: abstract value");
}
Caml_state->compare_unordered = 0;
res = compare(v1, v2);
if (Caml_state->compare_unordered && !total) return UNORDERED;
if (res != 0) return res;
break;
}
default: {
mlsize_t sz1 = Wosize_val(v1);
mlsize_t sz2 = Wosize_val(v2);
/* Compare sizes first for speed */
if (sz1 != sz2) return sz1 - sz2;
if (sz1 == 0) break;
/* Remember that we still have to compare fields 1 ... sz - 1. */
if (sz1 > 1) {
if (sp >= stk->limit) sp = compare_resize_stack(stk, sp);
struct compare_item* next = sp++;
next->v1 = v1;
next->v2 = v2;
next->size = Val_long(sz1);
next->offset = Val_long(1);
}
/* Continue comparison with first field */
v1 = Field(v1, 0);
v2 = Field(v2, 0);
continue;
}
}
next_item:
/* Pop one more item to compare, if any */
if (sp == stk->stack) return EQUAL; /* we're done */
struct compare_item* last = sp-1;
v1 = Field(last->v1, Long_val(last->offset));
v2 = Field(last->v2, Long_val(last->offset));
last->offset += 2;/* Long_val(last->offset) += 1 */
if (last->offset == last->size) sp--;
}
}
}
The code here is the skeleton to compare two elements tag-wise. The code omitted is details of specific tag cases. The stack is to store elements to compare, getting from compound values.
At this moment, I am not clear when elements are pushed into the stack. Begin_roots2(root_v1, root_v2); run_pending_actions(stk, sp); is doubty.
value and tag
OCaml value is stored as a value in memory at runtime. value and tag functions, e.g. Is_long and Tag_val are defined in runtime/caml/mlvalues.h. OCaml manual explains tags in Chapter 22 Interfacing C with OCaml. RWO has a clear explanation in chapter 23 Memory Representation of Values. Here is my recap:
Memory value can be an immediate integer or a pointer to other memory. An OCaml value of primitive types e.g. bool, int, unit encodes to an immediate integer. The rest uses a pointer to store the extra blocks. The last bit of a memory word is used to identify them: 1 marks immediate integers and 0 marks a pointer. OCaml enforces word-aligned memory addresses.
A block, which a pointer value points to, contains a header and variable-length data. The header has the size of the block and a tag identifying whether to interpret the payload data as opaque bytes or OCaml values.
Here is a rusty table pairing the summary from RWO and the handling case from compare.c.
| OCaml type | Value/Tag | Compare case |
|---|---|---|
| int | immediate | Is_long |
| enforced lazy value | Forward_tag | via Forward_val |
| abstract datatype with user functions | Custom_tag | via ->compare_ext |
| function (closure) | Infix_tag | via Closure_tag |
| string | String_tag | case String_tag |
| float | Double_tag | case Double_tag |
| float array | Double_array_tag | case Double_array_tag |
| abstract datatype | Abstract_tag | invalid abstract value |
| function (closure) | Closure_tag | invalid functional value |
| (handling effects inside callbacks) | Cont_tag | invalid continuation value |
| object | Object_tag | via Oid_val |
Discussion
Some omitted code in compare.c above is for GC interrupts. It's heavily discussed in ocaml/#12128.
Polymorphic compare is also dicussed in e.g. OCaml Discuss removing-polymorphic-compare and even over a decade ago.
The post makes a rough but clear explanation. Only use it with care.
Map, Set and Hashtables
What are exact functions required for distinct data containers?
Afterr all, what collections are in Base and Core?
| Base | Core | Stdlib | Kind | Requiring | Comment |
|---|---|---|---|---|---|
Applicative | / | functor | base lib | ||
Array | Array | Array | std | ||
Avltree | / | low-level | |||
Backtrace | Printexc.raw_backtrace | system | |||
Binary_search | / | interface | |||
Binary_searchable | / | functor | |||
Blit | Blit | / | std | bit-block transfer | |
Bool | Bool | Bool | std | ||
Buffer | Buffer | std | |||
Bytes | Bytes | Bytes | std | ||
Char | Char | Char | std | ||
Comparable | / | functor | |||
Comparator | / | functor | |||
Comparisons | / | interface | |||
Container | Container_intf | / | functor | ||
Either | Either | Either | std | ||
Equal | / | interface | |||
Error | Error | / | std | ||
Exn | exn | std | |||
Export | / | wrap | undoc | ||
Field | / | std | |||
Float | Float | Float | std | ||
Floatable | / | interface | |||
Fn | / | std | |||
Formatter | Formatter | std | |||
Hash | / | std | hash primitives | ||
Hash_set | Hash_set | / | container | compare, sexp_of, hash | |
Hashable | Hashable | / | interface | module trait | |
Hasher | / | interface | just t and hash_fold_t | ||
Hashtbl | Hashtbl | container | compare, sexp_of, hash | ||
Identifiable | Identifiable | / | functor | ||
Indexed_container | Indexed_container | / | interface | ||
Info | Info | / | std | ||
Int | Int | Int | std | ||
Int32 | Int32 | Int32 | std | ||
Int63 | Int63 | / | std | ||
Int64 | Int64 | Int64 | std | ||
Int_conversions | / | std | |||
Intable | / | interface | |||
Int_math | / | functor | |||
Invariant | / | interface | |||
Lazy | Lazy | Lazy | std | ||
Linked_queue | Linked_queue | Queue | container | ||
List | List | container | |||
Map | Map | Map | container | compare, sexp_of | balanced binary tree over a totally-ordered domain |
Maybe_bound | Maybe_bound | / | std | ||
Monad | / | functor | |||
Nativeint | Nativeint | / | std | ||
Nothing | Nothing | / | std | ||
Option | Option | Option | std | ||
Option_array | Option_array | / | std | ||
Or_error | Or_error | / | std | a specialization of the Result type | |
Ordered_collection_common | Ordered_collection_common | / | trait | ||
Ordering | Ordering | / | std | ||
Poly | Stdlib | std | |||
Pretty_printer | / | std | for use in toplevels | ||
Printf | Printf | Printf | std | ||
Queue | Queue | Queue | std | A queue implemented with an array | |
Random | Random | std | |||
Ref | Ref | 'a ref | std | ||
Result | Result | Result | std | ||
Sequence | Sequence | Seq | std | ||
Set | Set | Set | std | Sets based on Comparator.S | |
Sexp | Sexp | / | std | ||
Sexpable | Sexpable | / | functor | ||
Sign | Sign | / | std | ||
Sign_or_nan | Sign_or_nan | / | std | ||
Source_code_position | Source_code_position | / | std | ||
Stack | Stack | Stack | std | ||
Staged | / | std | |||
String | String | String | std | ||
Stringable | Stringable | / | interface | ||
Sys | Sys | Sys | std | ||
T | / | interface | |||
Type_equal | Type_equal | / | std | to represent type equalities that the type checker otherwise would not know | |
Uniform_array | Uniform_array | / | std | guaranteed that the representation array is not tagged with Double_array_tag | |
Unit | Unit | unit | std | ||
Uchar | / | std | |||
Variant | / | std | used in [@@deriving variants] | ||
With_return | / | std | |||
Word_size | / | std | |||
Base_internalhash_types | / | std | base.base_internalhash_types lib | ||
Md5_lib | / | std | base.md5 lib | ||
Arg | Stdlib.Arg | std | core lib; Command module is generally recommended over this | ||
Bag | / | container | |||
Bigbuffer | / | std | Extensible string buffers based on Bigstrings | ||
Bigstring | / | std | String type based on Bigarray | ||
Bigsubstring | / | std | Substring type based on Bigarray | ||
Bin_prot | / | interface | |||
Binable | / | functor | |||
Blang | / | std | |||
Bounded_index | / | std | unique index types with explicit bounds and human-readable labels | ||
Byte_units | / | std | |||
Command | / | std | |||
Container | / | interface | |||
Core_stable | / | std | |||
Date | / | std | |||
Day_of_week | / | std | |||
Debug | / | std | |||
Deque | / | container | |||
Doubly_linked | / | container | |||
Fdeque | / | container | |||
Filename | / | std | |||
Float_with_finite_only_serialization | / | std | |||
Fqueue | / | container | |||
Gc | Gc | std | |||
Hash_queue | / | container | |||
Heap_block | / | std | Core.heap_block lib | ||
Hexdump | / | std | |||
Host_and_port | / | std | |||
Immediate_option | / | std | |||
In_channel | / | std | Stdio.In_channel | ||
Interfaces | / | std | |||
Md5 | / | std | |||
Month | / | std | |||
Mutex | / | std | |||
Only_in_test | / | std | |||
Optional_syntax | / | std | provided by ppx_optional | ||
Out_channel | / | std | Stdio.Out_channel | ||
Percent | / | std | |||
Perms | / | std | |||
Pid | / | std | |||
Printexc | Printexc | std | |||
Quickcheck | / | std | |||
Quickcheckable | / | std | |||
Robustly_comparable | / | std | |||
Set_once | / | std | |||
Sexp_maybe | / | std | Sexp.Sexp_maybe | ||
Signal | / | std | |||
Splittable_random | / | std | |||
Stable_comparable | / | std | |||
Stable_unit_test | / | std | |||
Substring | / | std | |||
Thread | / | std | |||
Time_float | / | std | |||
Time_ns | / | std | |||
Tuple | / | std | |||
union_find | / | container | |||
Unit_of_time | / | std | |||
Univ_map | / | container | |||
Validate | / | std | |||
Weak | / | std |